kfifo 是 Linux Kernel 中一個 First-In-First-Out 的架構,跟昨天的範例不同,不是一個 Linked List,就只是一段記憶體,但是他是 First-In-First-Out,且允許 One-Producer-One-Consumer,是什麼資料結構都無所謂,我們多看例子就是希望可以自己設計或者了解 Concurrent 的程式在不同資料結構中,該如何去作設計
從資料結構開始看
struct __kfifo {
unsigned int in; // in: kfifo_put() 塞資料進去的位置
unsigned int out; // out: kfifo_get() 取資料出來的位置
unsigned int mask; // 有多少個 Element
unsigned int esize; // the size of the element managed by the kfifo,雖然是連續的記憶體,但他裡面最小單位是 esize
void *data; // 那段連續的記憶體
};
// 總之,在程式中有很多涵式,需要直接操作這段記憶體,所以把他宣告成 union
#define __STRUCT_KFIFO_COMMON(datatype, recsize, ptrtype) \
union { \
struct __kfifo kfifo; \
datatype *type; \
const datatype *const_type; \
char (*rectype)[recsize]; \
ptrtype *ptr; \
ptrtype const *ptr_const; \
}
// Kernel 中不知道為什麼,很喜歡寫出 ptrtype 之類的,然後讓他們再變成宣告的型態,我理解這是一種 Template 的表現 ......
#define __STRUCT_KFIFO(type, size, recsize, ptrtype) \
{ \
__STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \
type buf[((size < 2) || (size & (size - 1))) ? -1 : size]; \
}
#define STRUCT_KFIFO(type, size) \
struct __STRUCT_KFIFO(type, size, 0, type)
這邊我覺得也還看不出什麼東西,就是要先了解一堆變數的命名,但還有一堆變數要理解
// 哪些記憶體已經被使用過了,看到 `recsize` 是指 record size,而 `rectype` 則是指 record type
#define kfifo_recsize(fifo) (sizeof(*(fifo)->rectype))
// 這邊我不是很懂為什麼要加一????
#define kfifo_size(fifo) ((fifo)->kfifo.mask + 1)
如果有看參考的那篇文章會發現,在之前的版本中,結構中存在 spinlock_t *lock 的元素,這是用在多個 Thread 時候執行同一個動作 put 或 get 的情況。
但如果是兩個 Thread ,一個 put 一個 get ,這樣 1P1C, One-Producer-One-Consumer,不需要上鎖,這就是kfifo Lock-Free 的地方
目前看來 spinlock_t lock 已經被獨立出去,如有需要請自己再行傳入,在講述 API 的時候會介紹他被獨立到什麼涵式去,又該如何使用
#define kfifo_init(fifo, buffer, size) \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
__is_kfifo_ptr(__tmp) ? \
__kfifo_init(__kfifo, buffer, size, sizeof(*__tmp->type)) : \
-EINVAL; \
})
int __kfifo_init(struct __kfifo *fifo, void *buffer,
unsigned int size, size_t esize)
{
size /= esize;
// 強迫對齊 2 的 N 次方
if (!is_power_of_2(size))
size = rounddown_pow_of_two(size);
fifo->in = 0;
fifo->out = 0;
fifo->esize = esize;
fifo->data = buffer;
if (size < 2) {
fifo->mask = 0;
return -EINVAL;
}
// 我們終於知道為什麼 mask 要加一了,因為初始化的時候被減一 ==....
fifo->mask = size - 1;
return 0;
}
初始化沒啥重點,只是告訴我 mask 到底是什麼東西,趕快開始看怎麼操控 in 跟 out 吧
kfifo_put這是把以前使用涵是的地方作一些修改,延伸出來的涵式
__kfifo_put -> kfifo_in
__kfifo_get -> kfifo_out
kfifo_put -> kfifo_in_spinlocked
kfifo_get -> kfifo_out_spinlocked
3, 4 的修改就是我最開始提到的,以前需要在初始化就把 Lock 傳進來,但現在不用,有需要使用到的時候在傳就好
以下可以直接挑有中文註解的地方閱讀一下就好,完全不知道 kfifo_put 是要拿來幹麻,但接下來 kfifo_in 會使用到的涵式,kfifo_put 也有用到,所以我們要看的只是那些涵式的解析
#define kfifo_put(fifo, val) \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
typeof(*__tmp->const_type) __val = (val); \
unsigned int __ret; \
size_t __recsize = sizeof(*__tmp->rectype); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
if (__recsize) \
__ret = __kfifo_in_r(__kfifo, &__val, sizeof(__val), \
__recsize); \
else { \
__ret = !kfifo_is_full(__tmp); \
if (__ret) { \
(__is_kfifo_ptr(__tmp) ? \
((typeof(__tmp->type))__kfifo->data) : \
(__tmp->buf) \
)[__kfifo->in & __tmp->kfifo.mask] = \
*(typeof(__tmp->type))&__val; \
smp_wmb(); \
__kfifo->in++; \
} \
} \
__ret; \
})
老實說這邊我還是看不太懂 size_t __recsize = sizeof(*__tmp->rectype); 是什麼,反正他就是在講已經有多少 record 被使用了
這裡看到 mask 這樣設計一個很屌的地方,可以單純透過 & 就知道要把資料塞在哪 __kfifo->in & __tmp->kfifo.mask
unsigned int __kfifo_in_r(struct __kfifo *fifo, const void *buf,
unsigned int len, size_t recsize)
{
// kfifo_unused 是用來計算還沒使用到的 elements
// 非常單純的 Total Size - Current Size
// (fifo->mask+1) - (fifo->in - fifo->out)
//
// len + recsize 代表的是 [buffer size] + [被使用過的 record]
// 這樣看其實很難理解,因為一般直覺的想法是:
// 「要塞入的資料多長 v.s. 還剩多少空間」
// 但有一個重點,我猜這邊是因為他是環狀的結構,所以還要加上被使用過得資料有多少,只要還沒被使用過,那麼那筆資料最好就不要亂動,所以只能從被使用過得資料開始
if (len + recsize > kfifo_unused(fifo))
return 0;
// 這是一個 helper 涵式,我不知道怎麼形容這個東西 ...,就跟初始化的時候一樣,為了要把 Template 之類的東西丟進來,把什麼東西都變成參數
// 如果限縮 kfifo 的使用條件的話,可以展開成以下的形式
//
// fifo->data[fifo->in & fifo->mask] = (unsigned char)len;
// if(recsize)
// fifo->data[(fifo->in+1) & fifo->mask] = (unsigned char)len>>8;
__kfifo_poke_n(fifo, len, recsize);
// 較長
// 見以下程式碼
kfifo_copy_in(fifo, buf, len, fifo->in + recsize);
fifo->in += len + recsize;
return len;
}
static void kfifo_copy_in(struct __kfifo *fifo, const void *src,
unsigned int len, unsigned int off)
{
unsigned int size = fifo->mask + 1;
unsigned int esize = fifo->esize;
unsigned int l;
// off 是 fifo->in + recsize
off &= fifo->mask;
if (esize != 1) {// 一朝回到解放前,終於要算出真正的容量了
off *= esize;
size *= esize;
len *= esize;
}
// min(buffer 大小, ????)
l = min(len, size - off);
// copy 兩次,檢查是否還有要 copy 的東西,因為 l 並不一定是 src 的 size
memcpy(fifo->data + off, src, l);
memcpy(fifo->data, src + l, len - l);
/*
* make sure that the data in the fifo is up to date before
* incrementing the fifo->in index counter
*/
smp_wmb();
}
kfifo_in看了一堆東西不知道 kfifo_put 的意義何在,完全沒有看到 Concurrency 的點,
#define kfifo_in(fifo, buf, n) \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
typeof(__tmp->ptr_const) __buf = (buf); \
unsigned long __n = (n); \
const size_t __recsize = sizeof(*__tmp->rectype); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
(__recsize) ?\
__kfifo_in_r(__kfifo, __buf, __n, __recsize) : \
__kfifo_in(__kfifo, __buf, __n); \
})
// 沒有 record size 的狀況
unsigned int __kfifo_in(struct __kfifo *fifo,
const void *buf, unsigned int len)
{
unsigned int l;
l = kfifo_unused(fifo);
if (len > l)
len = l;
kfifo_copy_in(fifo, buf, len, fifo->in);
fifo->in += len;
return len;
}
到目前知道他 put 是藉由操控 in 來決定,他們其實也沒有作模數運算,就是透過一連串的加減乘除來完成而已,有充分利用 unsigned int 的特性,且他可以去覆寫以前的資料
原理還是看一下人家的介紹就好了,參考 巧夺天工的kfifo(修订版)
總之,就是大致上了解了可以透過以下幾點
in out
綜合以上兩點,就可以去實現了
那麼再來就是要看怎麼把這樣的設計應用到 Thread Pool 了嗎????這個我再考慮一下,因為已經有兩篇非常完整的介紹
我們一言以蔽之,把 Thread Pool 共用的 Work Queue 轉移到每個 Thread 中,大家都有各自的 Work Queue,每個 Thread 都從自己的 Work Queue 進行 get 操作,只有 Main Thread 會對他進行 put 操作,如此就是有好幾個 kfifo 的概念,只是把他的概念應用在 Queue 中
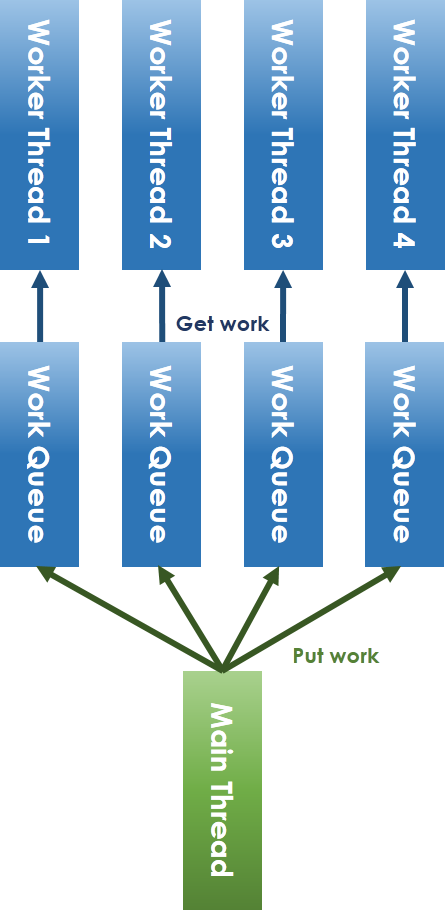
更多實作自行參考 xhjcehust/LFTPool 專案,專案中的實作不只是 Concurrent Thread Pool ,還有考慮 Load Balance 的概念,至於 Thread 之間的通訊是使用 Signal
BTW 我自己看了一堆 DP 的題目,結果自己都想不太出來== 所以看 Concurrent Project 可以學會如何設計嘛,可能要看非常的多才可以@@
因為中秋節要聚餐,所以這一章就這樣就好了吧~~


 iThome鐵人賽
iThome鐵人賽